DataCon2022软件安全赛道WriteUp
DataCon2022软件安全赛道WriteUp
Powershell反混淆-Level01
一、题目介绍
1.1 题目背景
PowerShell是攻击者常用的脚本,通常带有大量的混淆,导致检测、分析十分困难。选手通过分析主办方提供的混淆PowerShell文件,尝试反混淆得到PowerShell样本中预先植入的flag。
1.2 题目要求
PowerShell样本数据集包含利用各种混淆手段混淆后的PowerShell样本1000个,选手需要开发自动化分析工具,提取其中植入的flag。
数据集分两个阶段发放,第一阶段数据集A包含800个基于非恶意样本改造的样本,第二阶段数据集B包含200个特殊设计的混淆样本,其中包含实际的有潜在【破坏性】的恶意样本改造的样本。因此选手需在可控的隔离环境中进行分析测试,规避潜在的安全威胁。
1.3 数据说明
公开数据集中每个文件以样本内容的sha256值命名,没有后缀,文件内容为混淆过的PowerShell文件。样本文件中的flag标记形式为:”ip:255.255.255.255“(不包括前后双引号,前缀统一为ip:,紧跟的数字为合法IP地址范围内可变值)。
⚠️注意事项:一个样本只包含一个flag,同一个样本提交多个flag,系统只会根据第一个flag判分。
二、解题思路
2.1 样本分析与分类
在对题目逐渐深入后,我们发现大部分的样本都存在IEX指令。同时经过测试,我们发现很多样本再去除IEX指令后,直接载入PowerShell中进行模拟执行一次或若干次,即可得到隐藏的flag。而IEX也并非为可读明文的形式,往往也存在被混淆的现象,于是我们从样本和网络中收集了一些IEX的变形,形成IEX识别名单。
1 | |
当然在识别过程中,为应对部分字符串混淆的情况会将+、"、'、```等字符去除,以更多地匹配IEX指令。
根据以上发现,我们以可识别IEX的数量和位置信息为分类依据,将800个数据进行如下分类:
- 无可识别IEX的样本
- 通过字符运算混淆IEX的样本
- 模拟执行后存在IEX的样本
- 存在可识别IEX的样本
- IEX指令位于样本首尾的样本
- IEX指令位于样本中间的样本
2.2 总体思路
经过初期对PowerShell混淆与反混淆的多方调研,借鉴php反混淆的思路,结合静态规则匹配、动态执行以及AST语法树等技术,最终总结出本题的解题思路。
首先获提取样本中IEX数量、位置等信息,对样本进行分类。对不同类别的样本,分别进行反混淆处理,具体的反混淆方式有两种:一是对整个样本或是对样本中的某一行、某一参数值进行循环去除IEX再模拟执行,二是利用Invoke-Deobfuscation工具中的AST语法树对样本进行分析、反混淆。
解题思路的示意图,如下图所示。
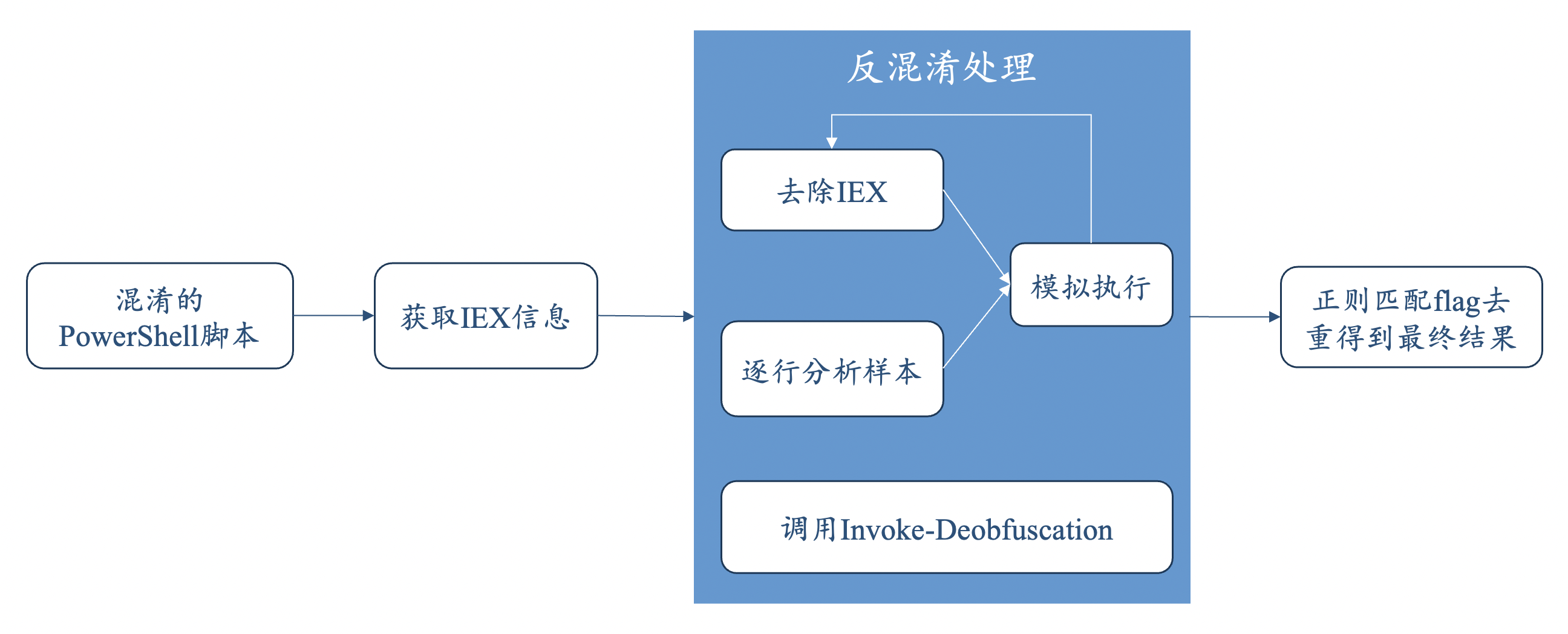
2.3 具体思路
2.3.1 循环去除IEX反混淆
循环去除IEX反混淆方法,是针对IEX位于样本首尾的情况。通过循环去除首尾IEX再模拟执行的方法获取最终flag,同时我们通过设置黑名单的方式防御恶意代码。具体的代码逻辑如下所示。
1 | |
在进行实际检测中,我们也发现了一些恶意文件下载、系统配置修改等恶意行为。为了减少这个恶意行为对自动化检测的影响,我们设定了一个简单的黑名单进行防御,具体黑名单如下。
1 | |
2.3.2 逐行分析
逐行分析,针对的是IEX在样本中间的情况。将样本进行分行处理,寻找可能存在flag的行,我们将其载入powershell模拟执行,在标准输出中查找flag信息,若没有查找到flag,我们会分析该行是否为赋值语句,对赋值语句中的参数值进行提取,后将其载入powershell模拟执行,最终提取flag。具体的逻辑如下所示。
1 | |
2.3.3 调用Invoke-Deobfuscation
对于剩余的情况,我们利用Invoke-Deobfuscation工具进行反混淆。根据《Invoke-Deobfuscation:AST-Based and Semantics-Preserving Deobfuscation for PowerShell Scripts》,Invoke-Deobfuscation工具是通过构建AST语法树的方式进行反混淆。该工具的混淆步骤主要有三步:Token解析、基于AST语法树反混淆、重命名与格式规范。其中,基于AST语法树的反混淆主要包括识别可恢复片段、基于调用的恢复、变量追踪和IEX去除与脚本重构四个部分。为了提高效率,我们去除了Invoke-Deobfuscation工具中重命名与格式规范部分的内容。

三、探索与后续
3.1 探索
通过多方调研,我们参考了论文《Invoke-Deobfuscation:AST-Based and Semantics-Preserving Deobfuscation for PowerShell Scripts》,尝试了使用Invoke-Deobfuscation、PowerDecode反混淆作为解决方案之一。
PowerDecode在处理一般混淆情况下有着不错的时间效率,但是当批量处理混淆脚本时,PowerDecode很不稳定,因此我们舍弃了这个方法。
Invoke-Deobfuscation作为官方建议的开源工具,在处理各种问题上有着不错的答案,但是由于AST树的构造需要耗费大量时间,尤其是当混淆脚本较大时,时间成本高,但是介于其优秀的反混淆能力,我们将其融入到我们的程序中,作为ip正确找到的保障。
3.2 后续
对一些ip混淆于多行的脚本依旧无法识别,由于我们使用的是’\n’的方式进行每行的分割,因此需要提出较为成熟的解决单行提取后存在语法断层导致语法错误的问题,我们计划使用符号匹配的方式进行解决,通过补充符号解决语法错误。
对于较大的文件,反混淆的过程中会因为时间过长从而超时。有些文件存在对抗的代码,我们可以通过设置一个黑名单全部禁止,从而降低时间代价。同时,大的文件建立的ast树所需的时间也就越长,我们打算实现无用代码的删除,从而达到压缩脚本体积,提高时间效率的目的,但是由于竞赛时间有限,我们未能完善。
四、总结
这次比赛我们选择了之前都未曾深入涉猎的领域,在解题时php反混淆启发了我们,让我们可以成功的取得很多ip结果。
后续可以通过完善模拟执行过程与对大文件在保证语法语意一致性的前提下进行切割从而降低时间代价,NLP的运用也可能可以帮助修复单行处理时语法语意错误的问题。
感谢主办方提供了这样一个优秀的平台和丰富的数据,极大的还原了真实环境下的各种状况,也感谢出题人不厌其烦地解答我们各种问题。在本次比赛中,我们不仅收获了知识,也找到了一些志同道合的朋友,也深刻体会到了不到最后不放弃的重要性。
Powershell反混淆-Level02
一、题目介绍
1.1 题目背景
PowerShell是攻击者常用的脚本,通常带有大量的混淆,导致检测、分析十分困难。选手通过分析主办方提供的混淆PowerShell文件,尝试反混淆得到PowerShell样本中预先植入的flag。
1.2 题目要求
PowerShell样本数据集包含利用各种混淆手段混淆后的PowerShell样本1000个,选手需要开发自动化分析工具,提取其中植入的flag。
数据集分两个阶段发放,第一阶段数据集A包含800个基于非恶意样本改造的样本,第二阶段数据集B包含200个特殊设计的混淆样本,其中包含实际的有潜在【破坏性】的恶意样本改造的样本。因此选手需在可控的隔离环境中进行分析测试,规避潜在的安全威胁。
1.3 数据说明
公开数据集中每个文件以样本内容的sha256值命名,没有后缀,文件内容为混淆过的PowerShell文件。样本文件中的flag标记形式为:”ip:255.255.255.255“(不包括前后双引号,前缀统一为ip:,紧跟的数字为合法IP地址范围内可变值)。
⚠️注意事项:一个样本只包含一个flag,同一个样本提交多个flag,系统只会根据第一个flag判分。
二、解题思路
2.1 数据分析
由于这道题的样本是人为精心改造的,我们在获取到200个数据集时,首先对数据进行了深入的分析,发现文件中的内容分为两种:一句话powershell命令和混淆后的powershell脚本。另外混淆的方式也多种多样,涉及字符串混淆、base64编码混淆、函数和对象的混淆等。
除了基本的混淆外,数据中的样本也携带实际的恶意行为,例如杀进程、杀运行界面;此外还存在一些对抗手段,例如休眠。
最后flag的位置也被出题人精心设计过,Flag的位置有些是在运行后的标准输出中,有些是在运行后将flag写入到一个文件中。除了上面正常的情况,还有一些flag隐藏在永远不会被使用的变量中,或者永远不会执行的代码片段,对于这种情况我们通过执行样本并不会得到最终的flag。
2.2 具体思路
在对数据进行深入分析以及多方面调研后,我们借鉴了静态分析领域符号执行的思想。第一步:先去除样本中的iex指令,然后利用PowerShell的解码能力对混淆后的样本进行去混淆,直到得到明文数据。第二步:对代码进行重构,删除明文数据中的有害/无用的代码,例如stop-process、| not-null等,避免恶意行为以及对抗手段;另外也对代码的逻辑进行了修改,解决flag藏在永远不会执行的代码片段中以及永远不会使用的变量中;最后就是通过正则表达式在执行后的输出内容中获取flag。总体思路的流程图如下:
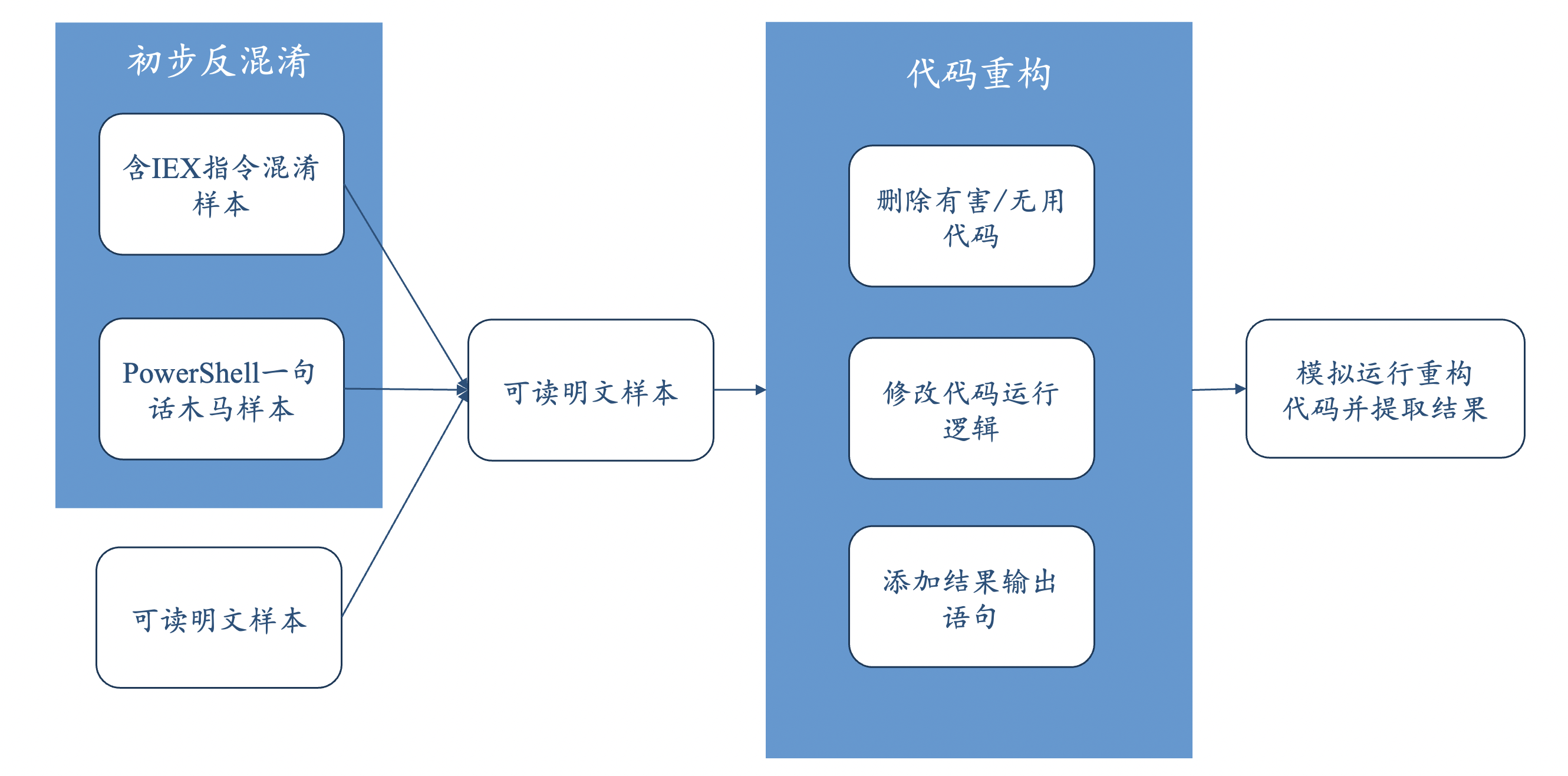
2.2.1 反混淆
根据我们对样本的统计,发现存在一些使用iex指令解码以及一句话PowerShell命令的样本,将他们恢复出来之后可以得到与其他样本相同的格式,所以第一步我们对整个样本集需要进行反混淆,接下来按照不同的混淆类别来进行详细说明
- 使用iex指令解码样本
对于使用iex指令解码的样本,我们套用level1的思路,对样本进行iex指令位置识别,iex指令删除,混淆部分载入PowerShell动态执行三个步骤,最后获得混淆前的明文样本。
- 一句话PowerShell命令样本
对于PowerShell一句话命令的样本,我们分析得到最终的解码流程:提取PowerShell一句话命令中使用Base64编码的内容E1,进行解码,得到明文D1;删除明文D1中存在的不可见字符后,在提取出其中包裹的Base64编码内容E2,进行解码,得到使用zlib进行编码的内容E3;最后对E3进行zlib default模式的解码得到中的明文M。
2.2.2 代码重构
代码重构部分是我们level2解题的重点。该部分主要分为三个步骤:有害/无用代码去除、判断语句逻辑修改、结果输出语句添加,接下来将逐步描述代码重构的三个步骤。
- 有害/无用代码去除
我们通过对样本数据的观察、统计,针对本次比赛的样本定义了无用/有害代码集。
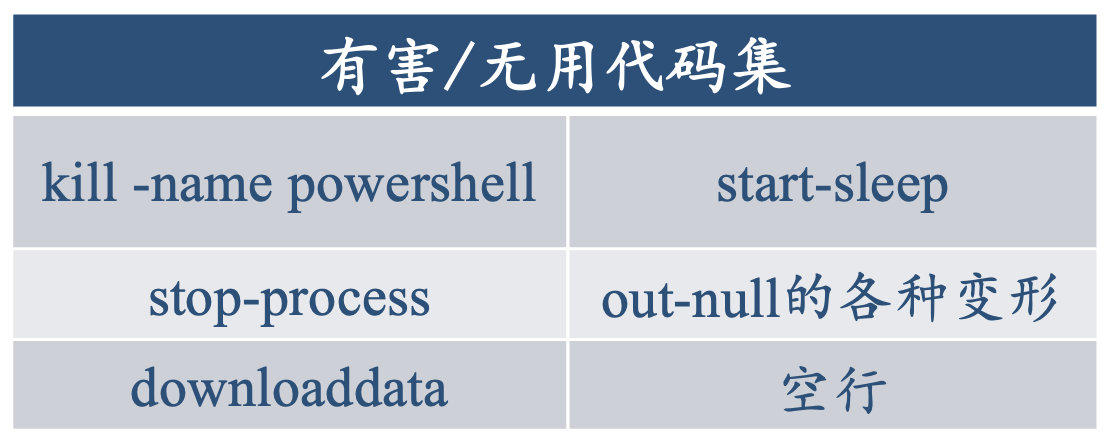
分行读取样本中的内容,判断是否符合无用/有害代码的特征,若符合则进行去除,反之保留在代码中。
- 判断语句逻辑修改
我们发现很多function中存在if-else语句,通过与出题人的交流和人工提取flag等方法,总结出需要修改判断语句为永真,才能全面地提取flag。
在PowerShell中if-else类型语句总共有三种标识,分别为if、elseif、else。首先我们会提取所有if-else语句,并去除原始样本中可能存在的换行影响;其次我们将所有的if-else语句的条件判断改为永真式if($True)。
本方法相较于其他方法的优势在于只需要着眼于条件判断的一行,不需要对整个if-else语句块进行识别,从操作难度与效率上来说,更加具有优势。
- 结果输出语句添加
根据我们对样本的分析,我们发现许多flag隐藏在变量之中,但原程序不支持直接输出(即使是我们删除了out-null之后),因而我们定义了一些程序分割点,在分割点处对最后一个参数的值进行输出。

2.2.3 运行获取结果
根据我们的分析,flag主要隐藏在参数值和生成的恶意文件中。因而我们获取flag的方式主要有两种,分别为重构代码运行结果识别读取flag,对本地新增文件内容识别读取flag。
首先,我们将记录当前文件目录下的所有文件;其次,模拟运行2.2.2中重构的代码,识别运行结果中的flag信息;对没有识别出flag的样本,我们会重新获取当前目录下的所有文件信息,对比查找新生成的文件,读取其中的内容,识别flag信息。
三、探索和后续
3.1 探索
由于构建的样本不仅混淆方法多,而且flag的位置也多种多样。我们最开始的想法是把所有变量的值通过解析代码获取到,然后将变量(variable name)用变量的值(variable value)替换,最后只运行一行或者一部分代码片段。通过这样的方式我们可以选择运行我们认为最有可能出现flag的代码片段,提高整体的速度,同时可以绕过一些对抗手段。
但是在实现后,发现情况比我们想象的要复杂很多,首先是有些变量的值,我们无法准确获取;其次在将变量(variable name)用变量的值(variable value)替换的时候,会存在漏过的情况,特别是将变量(variable name)作为参数传递给函数使用的时候。上述两步的效果也决定了我们最后选择代码片段运行的效果,经常遇到语法错误的情况,总计约可以处理10%的样本。
3.2 后续
我们在4核16G的windows机器上,花费约220秒就可以处理提供的200个样本,并且能够正确处理83%的样本。对于剩余无法处理的样本,我们进行深入分析,发现除了个别出题人在改造样本的过程中使样本损坏了,其他较多的是flag存储在变量中。因此我们在代码重构时,在合适的位置新增一条打印命令将该变量打印出来。目前只有当变量在函数体(function body)或者判断体结束的位置声明时,我们才添加一条打印命令,而实际中存储flag的变量有一部分并不在函数体/判断体结束的位置,所以基于位置判断是否需要添加打印命令是会存在漏过的情况。
对于这一块,我们后续的优化思路是根据变量的定义-使用情况来确定是否需要增加一条打印命令,具体来说就是判断一个变量在定义后,是否被使用过,如果没有使用过,那么我们就在该变量后面增加一条打印命令,这样就可以弥补基于位置新增打印命令的不足。
四、总结
正如探索部分的内容所述,我们前期由于方法不对,花了很多时间实现的代码效果并不好。目前的方案也是我们在距离比赛结束不到24小时才想出来的,最后取得了出乎我们意料的结果。如果我们能够更早采用目前的方案,留给我们更多的时间优化,相信我们可以取得更好的结果。
最后就是感谢主办方举办这次比赛, 让我们不仅学到了新的技术知识,也真正感受到不到最后时刻一定不要放弃,同样也感谢出题人在比赛过程中的耐心解答。
软件供应链安全分析-AndroidAPP组成分析
一、题目介绍
Android第三方库是广告商、支付公司、社交、推送平台和地图服务商等第三方服务公司为便App开发人员使用其服务而开发的工具包,包括广告、支付、统计、社交、推送、地图等类别。越来越多的App通过集成第三方库来丰富自身功能。
但是第三方库的引入,在给App带来功能支持的同时,也有可能会引入安全问题,例如安全漏洞和隐私滥用等。
在本题中,选手需要通过分析主办方所提供的App文件,提取出App中的第三方库信息,包括库名称、库版本、库识别依据等信息。
此外,一些第三方库服务需要开发者通过实名注册账户向服务提供商申请id和key来获取。这一类的id和key我们将其作为开发者的标识符id,这类信息会硬编码在App文件中。这类信息的提取将会作为题目附加分数项。
1 | |
二、解题思路
我们的思路如下如所示。首先对APK进行反编译,然后分别基于Manifest配置文件、动态链接库以及源代码和包名提取SDK,最后将提取的信息进行清洗和匹配,输出结果。
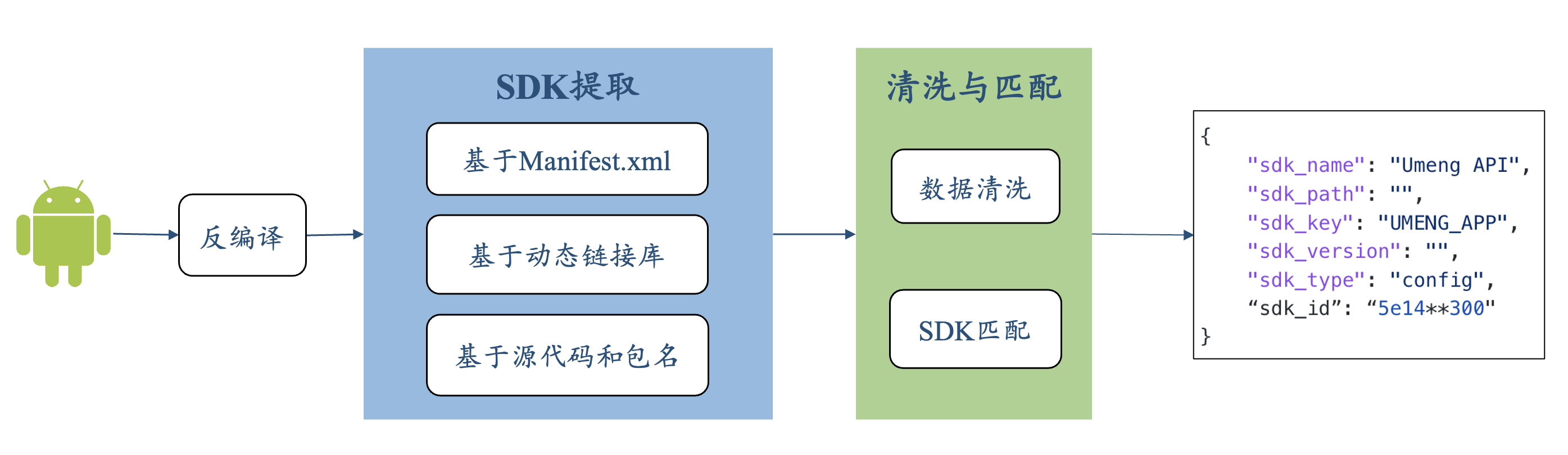
2.1 APK文件结构
APK文件是安卓系统的一个安装程序包,其本质是是一个ZIP文件,将后缀改为ZIP然后解压就可以获取到如下的文件目录:
1 | |
2.2 APK反编译
对于安卓的dex可执行文件,进行反编译以分析代码。一种方法是先通过APKtools提取文件,然后用dex2jar将字节码转化为jar包,然后再用jd进行反编译;另一种方法是使用jadx直接将apk转化为源代码,得到sources和resources目录。我们选择了后者。
1 | |
2.3 SDK信息收集
经过我们的分析发现,与组件相关的数据有些在AndroidManefest.xml,该文件不仅包含了SDK的名字,也包含了一些SDK ID的信息;另外就是反编译后的source文件下面的源代码和代码目录也包含了SDK的信息;最后就是APK运行时使用到的动态链接库,该内容全部存储在lib目录下。
2.3.1 AndroidManifest.xml
我们注意到,在AndroidManifest.xml文件中,meta-data标签会定义一些常量键值对,在代码中通过API获取。很多SDK密钥或标识符都定义在这里,例如:
1 | |
有些则定义了版本信息,如下,这里的版本值通过"@ingeger/"引用了values/integers.xml定义的常量,在提取时需要到对应xml标签下进行解引用。
1 | |
我们提取了带有KEY SECRET ID VERSION等关键字的键值对,将关键字去掉后进行模糊匹配,然后输出结果。
2.3.2 源代码与包名
在jadx反编译的java代码中,我们发现许多private static final String定义的用户密钥和版本信息。
1 | |
提取变量名包含’APPID’, ‘SDK’, ‘APP_ID’, ‘KEY’, “UNIT_ID”, “UID”, “TOKEN”, “VERSION”的变量定义语句后,将包名与变量名关键部分放到SDK数据库中进行模糊匹配。
APK中所有的类可以通过apkanalyzer导出,这里我们直接用jadx反编译的文件路径进行分析,分割类名后进行SDK Name模糊匹配。类名的提取有一些讲究,一般情况下跳过顶级域名取三级class即可。同时,还需要跳过apk本身的包名和Android与java自带的包,如android.*、androidx.*、java.*等
1 | |
2.3.3 提取动态库名称
JNI库是为了提升运行效率而生成的原生代码,用C语言或C++编写,放在对应架构目录下。许多libname都带有一些对应组件的名字,例如
1 | |
从中我们就可以看到有weibosdk core、AMapSDK(高德地图)、Agora等SDK,其中有些还带有版本信息。同时,根据库名可以识别出加固信息,如下所示。
1 | |
遍历动态库目录下所有lib*.so文件,利用正则提取版本信息,并将剩余部分与SDK数据库进行模糊匹配,得到匹配结果。
对于一些被混淆的明显无意义结果,如libaab.so、libdddd.so、libxxxxx.so,我们通过统计字符出现的种类将其过滤掉。有一些词语容易被识别为版本,如3d, v8, x86, x64, armeabi-v7a,我们维护一个黑名单过滤掉。
2.4 SDK Name模糊搜索
2.4.1 数据的爬取
我们数据的主要来源有:
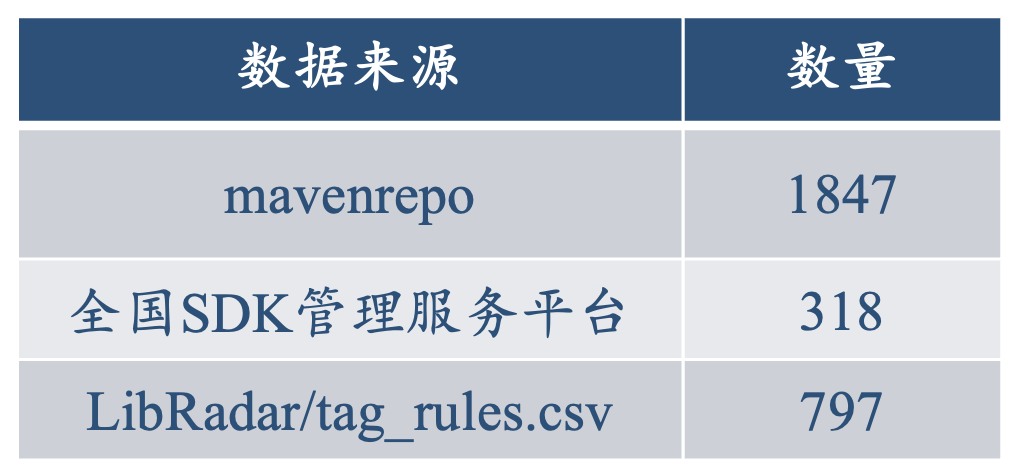
值得一提的是,对于国内SDK的数据库,爬到的只有中文的SDK名和厂商名,如
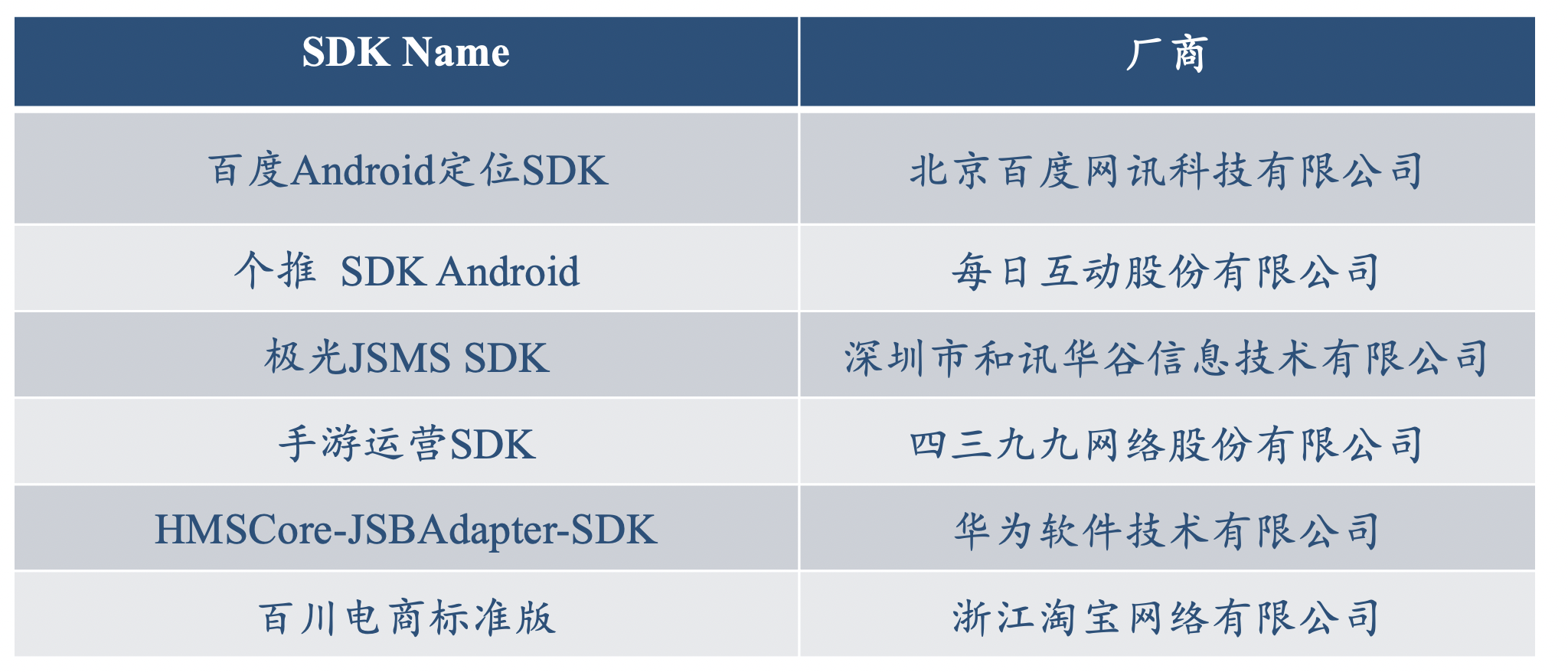
而匹配的目标则是英文标识符:
1 | |
为此,我们把SDK的名字、厂商分别翻译为英语、拼音后拼接到一起,提升子串的匹配能力。

2.4.2 模糊匹配算法
我们的模糊匹配采用了最长公共子串算法,由于动态规划的效率太低,我们改进为在后缀自动机上进行匹配。改进后的算法得到了可以容忍的时间复杂度,得以使我们扩增数据集。
多模板子串匹配算法(模板字符串的个数$k$,模板字符串的长度$m$,待匹配字符串的长度$n$)的后缀自动机构建伪代码如下:

(如果owners用set维护的话空间复杂度还可以降到$km$,如果构建自动机时维护owners,时间复杂度也可以降到$km$,但当时没有考虑这么多)
在匹配时只需要遍历被搜索串的后缀,在自动机上进行搜索。这样,构建的时间和空间复杂度为$O(km^2)$,其中n很小。而匹配的时间复杂度则由$O(kn*m)$降低为了$O(n^2)$,这个提升在k很大(模板个数很多),而$n$很小(待匹配串很短)的情况下是很显著的。在数据库有接近3000项时,只需要12分钟即可完成2000个APK的分析。
2.5 基于代码行为特征的检测
针对APK混淆的情况,由于包名、文件名和包结构都可能被改变,基于已知库的包名白名单是难以处理混淆代码的,因此需要寻找与名字无关的代码特征进行分析检测,而基于代码行为特征的检测是不会被混淆改变的,能够有效地处理混淆情况。
2.5.1 选择开源工具
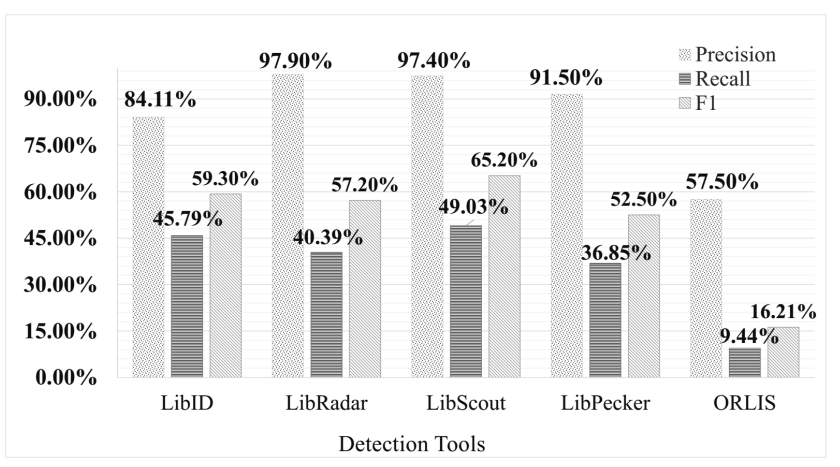
由于本次比赛时间不长,面对2000个目标apk,我们希望能够使用快速且准确的工具进行分析。通过调研各开源Android第三方库检测工具,我们发现Libradar最具高效性且实现成本较低,在实验尝试(Literadar)轻量版Libradar以及Libscout后,发现Literadar效果不错,而Libscout和其他大多开源工具没有提供特征数据库,需要人为收集大量Android apk进行特征提取,时间成本较大,综上,我们进一步安装Libradar进行分析。
GitHub - pkumza/LibRadar: LibRadar - A detecting tool for 3rd-party libraries in Android apps.
2.5.2 Libradar简介
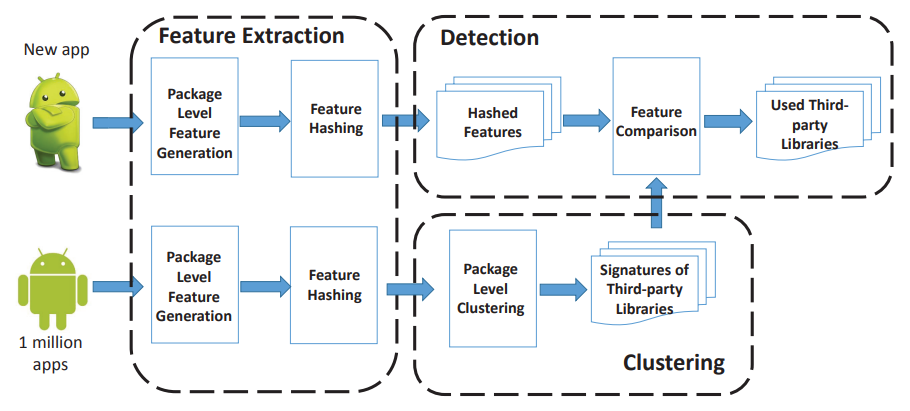
Libradar是一个基于API特性的Android第三方库检测工具。通过分析超过100万个Android 应用程序,Libradar选择了稳定的API调用特征以及文件夹目录的哈希值,并使用多级聚类来生成指纹库,在检测给定的新Android应用程序时只需静态分析和比较就可以快速获得其中的第三方库。
2.5.3 工具原理
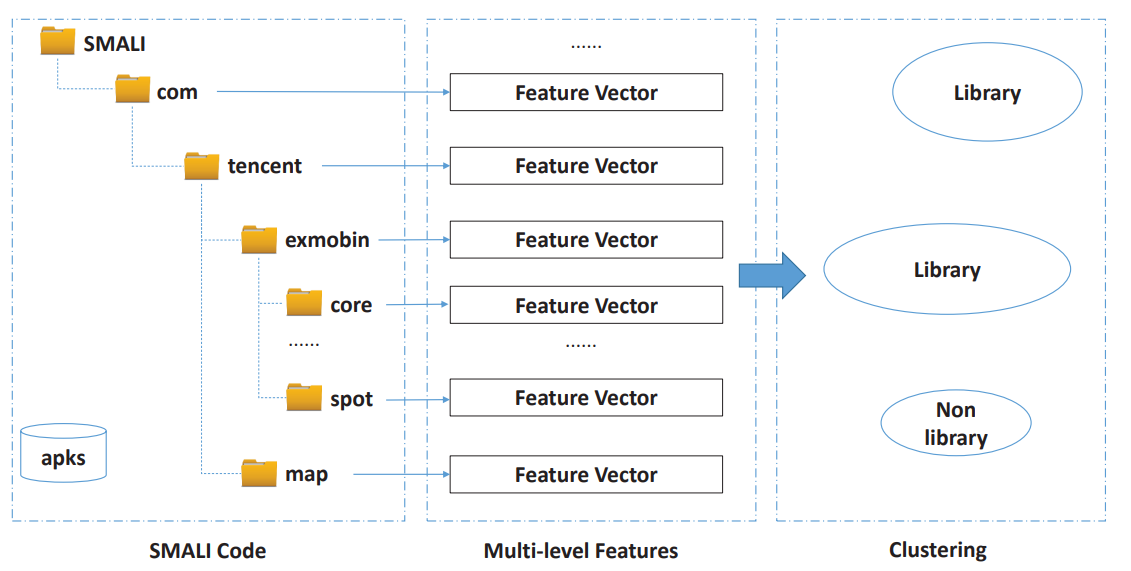
Libradar使用Apktool反编译Android应用程序为Smali代码。
使用特征哈希获取Smali代码中的各文件夹签名,提取包结构中的API总数和API类型,共同构建特征向量。(此类API特性在混淆过程中不会被修改,可以提供稳定且准确的指示)
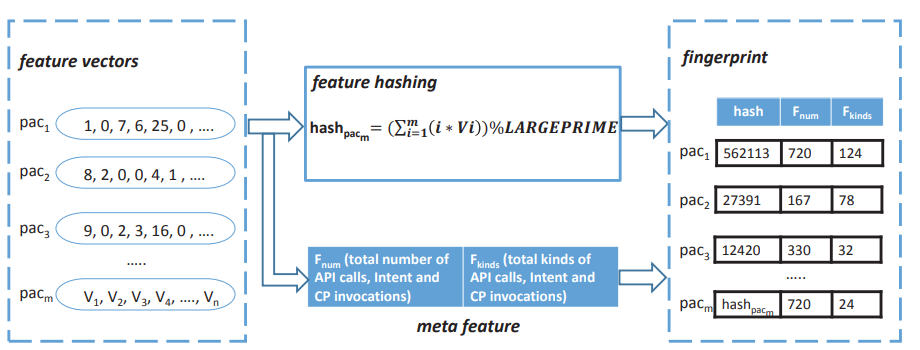
在生成指纹库阶段,对各个包提取的特征进行多级聚类,确定潜在库及其散列特征的列表;在分析给定应用阶段,将提取的每个文件夹的特征与指纹库进行比较,检测使用的第三方库。
2.5.4 使用及结果
2000个APK,880个检测无效(859个为空,21个失败),其余1120个都成功检测出第三方库。输出结果例子如下:一个检出库信息中library和package对应题目需要的sdk_name和sdk_path。

三、探索和后续
3.1 探索
3.1.1 开源工具库的调研
我们参考了论文[《A Systematic Assessment on Android Third-Party Library Detection Tools》](A Systematic Assessment on Android Third-Party Library Detection Tools | IEEE Journals & Magazine | IEEE Xplore),尝试并使用了Libradar、Libscout以及libpecker。由于Libscout特征数据库不全,需要人为收集才能达到好的效果,因此在时间成本的考虑下选择暂时放弃;之后安装Literadar进行实验,分析认为具备可用性后安装了Libradar作为答案的一部分。
3.1.2 字符串匹配算法的迭代
在字符串模糊匹配算法上,我们先尝试了最长公共子序列算法,发现它在没有合适匹配时会误分割产生错误的结果,如下所示。

于是我们改用了最长公共子串算法,但是会出现长单词夺取匹配的问题,如下,Framework的长度为9,夺走了本应该匹配到的GaodeMap:
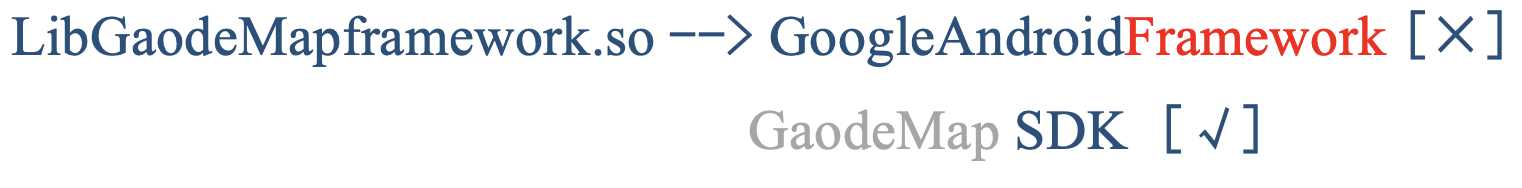
对此,我们的解决方法是维护一个常见的长单词黑名单如framework、android等,将长单词过滤后再进行匹配。我们设置的匹配阈值是:匹配长度大于7个字符或目标串总长度的70%,就输出结果。
3.2 后续
由于时间原因,我们的一些想法还未实现,如:
检测结果的进一步清洗与合并
对一些特殊处理、校验和错误的APK包进行分析、修复(此前全部跳过了)
1
badlist = ['220.apk', '1027.apk', '706.apk', '557.apk', '1411.apk', '99.apk', '814.apk', '1596.apk', '86.apk', '1621.apk', '1687.apk', '745.apk', '1075.apk', '723.apk', '626.apk', '113.apk', '721.apk', '463.apk', '574.apk', '1089.apk', '1355.apk']有些动态库名称被加密混淆,可以尝试从符号表、字符串表提取信息。
由于Libradar不能精确获取第三方库的版本信息,且在混淆代码的检测上效果并不优秀,后续可以改进它的匹配算法,统计更多的特征,收集Android apk数据,实现对版本的识别。
四、总结
感谢主办方提供了这个平台使我们学习和进步,感谢安卓出题人的耐心答疑和辛苦判题。通过本赛题,我们了解到了APK的结构和安卓第三方库的基本知识,通过赛方提供的推荐论文和自己的调研,我们学习到了各种检测第三方库的思想和方法,在实践操作上也得到了锻炼,甚至重温了以前学习的算法知识。比赛的过程中我们一直都没有放弃,即使比分落后第一名一大半的时候,师兄也一直在鼓励我,给我们加油,最后终于追了上去。虽然最后差了一点分数,但也是不错的结果了。
比赛结束后我们整理答案时,我发现主要问题还是数据库规模不够,很多SDK Name匹配不上。我们爬虫开的太晚(倒数第二天才想到增加数据量,最后一天才开始爬)。这也让我认识到在大数据研究中,数据量是基础。感谢DataCon提供的大数据安全实践的机会,让我对BigData有了更切实际的认识。